Reviewing my GPT-5 predictions
Earlier today (on August 7th), I realized that I was about to miss a golden opportunity to quickly test how calibrated I was about AI progress by predicting some GPT-5 benchmark scores. Upon realizing this, I dashed off some quick predictions based on a combination of then-current top benchmark scores and my intuition about how big a jump GPT-5 would be over o3, Grok 4, Claude Opus 4, and Gemini 2.5 Pro. You can see the predictions and current resolutions in the next section. My one sentence summary of their underlying sentiment is “progress continues apace along the trendline but without a discontinuous jump.”
My predictions #
If I had more time, I would’ve predicted on even more things. I especially regret not predicting METR’s time horizon benchmark results. But, as they say, done is better than perfect, so here’s what we ended up with.
| Benchmark | My Prediction | GPT-5 Result | Outcome |
|---|---|---|---|
| ARC-AGI 2 | 10% for >50% | 9.9% | ✅ Correct (low probability event didn’t occur) |
| SWE-Bench Verified | 70-80%: 64% / 80-90%: 30% / Other: 6% | 74.9% | ✅ Direct hit on highest probability range |
| FrontierMath | 20-30%: 45% / 30-40%: 40% / 40-100%: 10% / <20%: 5% | 32.1% (OpenAI) 24.8% (Epoch) |
⚠️ Second-highest probability range |
| Creative Writing | 75% to top leaderboard | Top of the leaderboard | ✅ |
| NYT Connections | 68% to top leaderboard | Pending | ⏳ Currently 7th place |
| CodeForces ELO | 40% for top 10 | Pending | ⏳ Unlikely to resolve |
Analysis & takeaways #
How did I do? #
Even without all my predictions having defined resolutions, I feel comfortable concluding that I did fairly well. As you can see below, I predicted meaningful, but incremental progress, on SWE-Bench Verified and FrontierMath (tiers 1-3). In the first case, my maximum probability range turned out to contain GPT-5’s actual performance right in the middle. For FrontierMath, GPT-5 just made it into my second most likely, slightly higher range when using “pro” mode and tools. Finally, I predicted that GPT-5 wouldn’t make a massive jump on ARC-AGI 2 from Grok 4 and was correct. For the unresolved predictions, my current bet is that GPT-5 will top the creative writing leaderboard (edit: it did), is a toss up for the connections one, and will not place top 10 in the world on CodeForces. So no major whiffs, although I may have over-estimated progress on NYT Connections a bit.
As mentioned above, I generated my predictions via hand-wavey trend line extrapolation. For each, I basically looked at how the most recent top models did relative to their predecessors and used that to make a rough guess of how much better GPT-5 would be assuming a similar trend. With the caveat that n=3 is very small, this methodology worked reasonably well for predicting GPT-5’s performance.
In terms of what this implies about AI progress, my main takeaway is kind of boring - GPT-5 is another impressive, on trend, step on a fast but predictable climb across a range of coding, math, and agentic benchmarks. It’s not a 0-1, game-changing inflection point, but it’s also not a sign of the brick wall we’ve been hearing about for years.
If we look beyond the benchmarks I made predictions for, the story is a bit more mixed, but overall holds up. On certain benchmarks not captured by my predictions, like Health Bench and economically important tasks, it made bigger jumps.
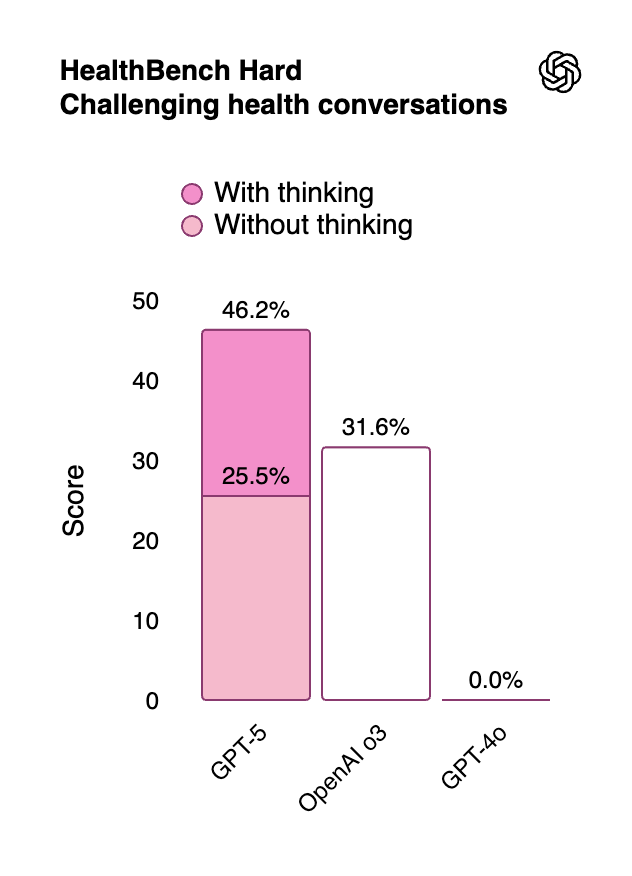 Source: OpenAI’s announcement post.
Source: OpenAI’s announcement post.
On others, like OpenAI PRs, it didn’t significantly improve on o3 and ChatGPT agent.
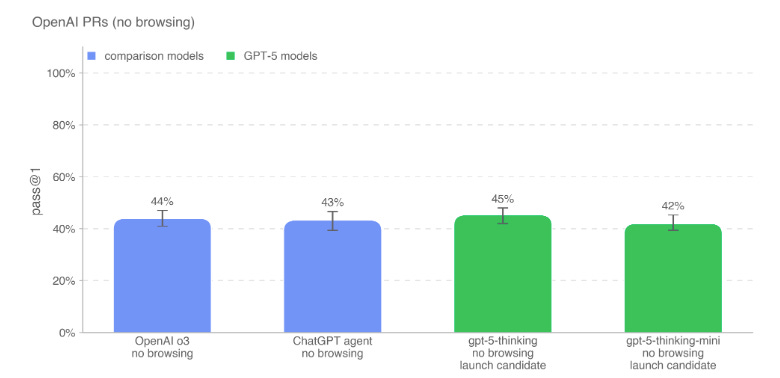 Source: OpenAI’s system card.
Source: OpenAI’s system card.
But, on the whole, especially factoring in the METR time horizon evaluation, “on trend” feels right as a conclusion.
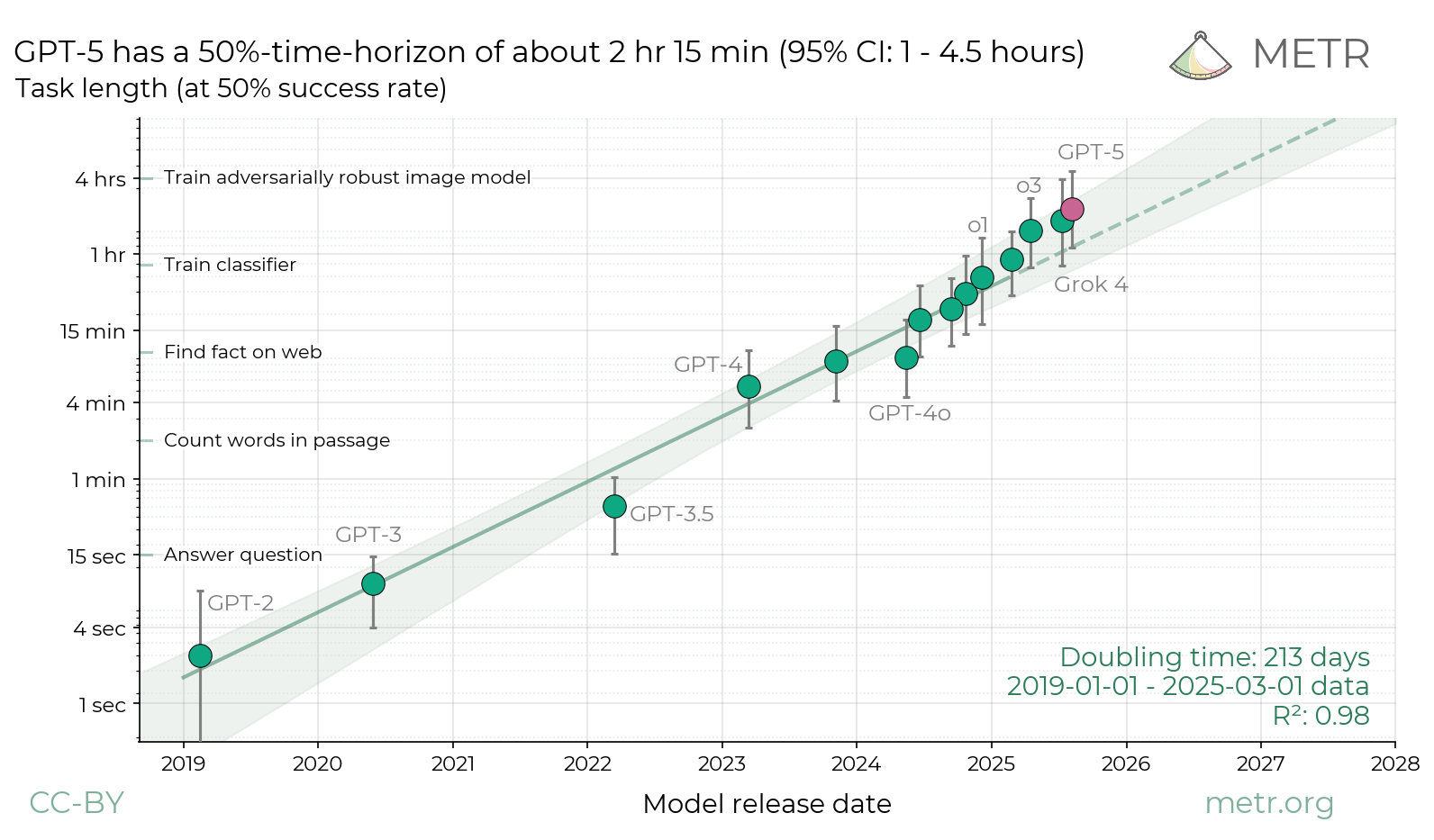 Source: METR’s GPT-5 post.
Source: METR’s GPT-5 post.
Going meta #
As I’ve written about previously (paywalled), I have become a lot more AGI-pilled over the past two years. I wish I could easily translate my “on trend” conclusion to an update about what to expect over the next few years, but I’m finding it surprisingly hard. Ultimately, the big question I (and others) want to know the answer to is whether predictable gains on these benchmarks result in general agents that can act as drop-in remote workers, recursive self-improvement, and geniuses in data centers.
But I increasingly feel like these static benchmarks aren’t sufficient for guessing that in advance. Instead, I think dynamic benchmarks like Claude (and now other models) Plays Pokemon and the BALROG benchmark capture better proxies for the missing capabilities we really should be monitoring. Going forward, for the purpose of monitoring general AI progress, I likely will pay more attention to these, complimented by work-relevant, domain-specific benchmarks.
What about the value of this exercise itself? Were the 30 minutes I spent nailing down predictions worth it? The 90 minutes I spent writing this post?
Philip Tetlock and others have written about how making prediction helps forecasters filter out the noise and really focus on what they concretely expect, and that resonates here. It’s very easy for me to get caught up in the fervor of how back we are or how over it is with every launch, but stepping back and focusing on predictions can help me escape the all-or-nothing mindset. For that reason, while I suspect this specific instance was not that valuable in isolation, the habit of making these sorts of predictions and reflecting on them feels valuable.
On the other hand, if I’m going to do such exercises in the future, I’ll spend more time picking prediction targets whose resolution can meaningfully move my views. As is probably clear from the above, my “on trend” conclusion didn’t provide zero new information, but it certainly didn’t maximize my information gain either.
Finally, when it comes down to it, if nothing else, making these predictions lets me feel superior to all the people who talk about how right they were in hindsight without showing the epistemic virtue of predicting beforehand! That’s priceless. (Kidding, mostly…)
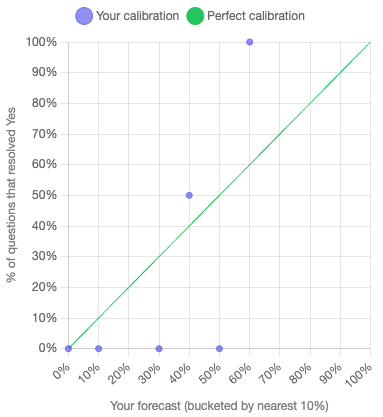
Appendix: Calibration Plot #